
基于Langchain搭建 Agent 流程解析与实战
欢迎来到这一期博客!最近我对agent比较感兴趣,想搭建一个全能的 AI Agent。不仅限于聊天,我希望它能帮我干活儿,比如查天气、订机票、分析数据……总之,就是一个真正的“AI助理”。
要实现这个目标,光靠一个LLM是不行的,它还得有“手”和“脚”——也就是连接现实世界、执行具体任务的能力。
在看完一系列教程之后之后,我决定继续使用LangChain 框架。所以,这篇博客就是我的学习笔记,记录一下如何使用 LangChain 来搭建一个初级的 Agent,以及它背后最核心的“工具调用”(Function Calling)逻辑。
LangChain的优势
在“万物皆可 LLM”的时代,我们为什么还需要一个像 LangChain 这样的框架?因为它精准地解决了大模型应用开发中的两大核心痛点:
-
解决了“整合”的痛点: 当前,大模型“百花齐放”(OpenAI, Gemini, Claude, Llama…),外部工具(API、数据库、搜索引擎)也五花八门。如果没有统一的框架,开发者每次想要切换模型或增加一个工具,都不得不重写大量的“胶水代码”。LangChain 提供了标准化的接口抽象,让我们摆脱了这种重复劳动。
-
提供了“组件化”的便利: LangChain 提供了大量标准化的组件(Components),如 Prompt 模板、模型 I/O、输出解析器(Output Parsers)、工具(Tools)等。这使得开发过程像“搭积木”一样,开发者可以专注于业务逻辑的编排,快速组合出一个完整的应用,极大提升了研发效率。
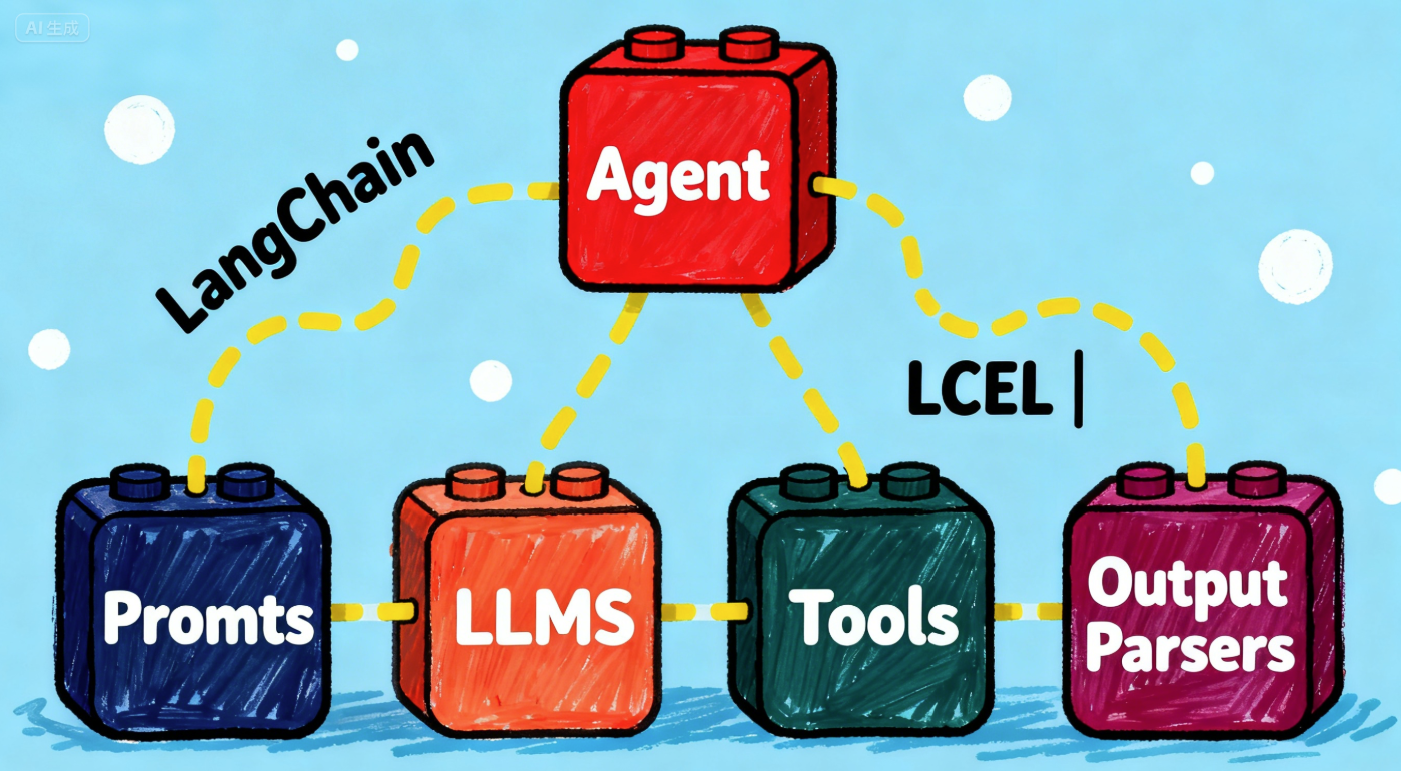
如何使用 LangChain 搭建 Agent
1. 到底什么是 Agent?
首先,Agent 不是 LLM,LLM 只是 Agent 的“大脑”。
一个 Agent 是一个能够自主决策和行动的系统。它会观察环境、思考下一步该做什么,并利用可用的工具去执行动作,直到完成目标。
目前,驱动 Agent 的核心逻辑大多基于 ReAct 模式,这是“Reason + Act”的缩写。
简单来说,ReAct 的流程就是:
-
Reason (思考):Agent(背后是 LLM)根据你的指令和当前情况,思考:“我该怎么做?我需要什么信息?我该用哪个工具?”
-
Act (行动):Agent 决定调用一个工具(比如搜索工具、计算器工具)。
-
Observation (观察):Agent 拿到工具返回的结果。
-
Repeat (循环):Agent 带着新拿到的结果,回到第1步,再次思考,直到任务完成。
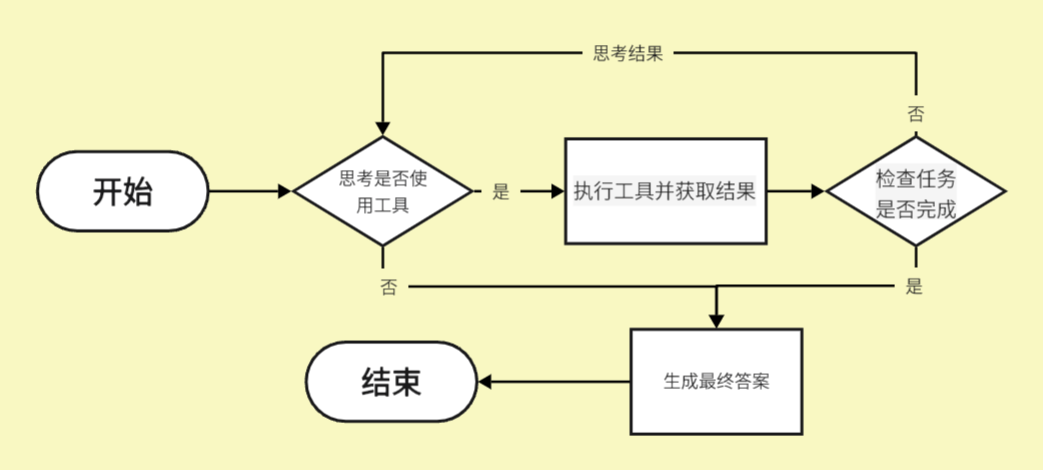
2. 构建 Agent 的四个核心步骤
要让一个 Agent 跑起来,至少需要三个核心组件:
-
模型 (Model):Agent 的“大脑”,负责思考(Reason)。
-
工具 (Tools):Agent 的“手脚”,负责执行(Act)。
-
代理执行器 (Agent Executor):负责管理 ReAct 循环,把“大脑”和“手脚”调度起来。
下面,介绍一下具体的agent构建流程。
Step 1: 自定义函数,也就是可用的工具 (Define Custom Functions)
Agent 的能力上限,取决于你给它多少好用的工具。LLM 本身不会看天气、不会执行代码,这些都需要我们通过“工具”赋予它。
在 LangChain 中,定义一个工具(Tool)非常简单,本质上就是封装一个 Python 函数。但有几个关键点必须包含:
-
清晰的函数定义:包括函数名和必要的传入参数(带类型注解)。
-
详细的用途描述:这是最关键的一步!你需要用自然语言(通常在 docstring 里)清楚地描述这个工具是干什么用的、什么时候该用它、参数代表什么。Agent 的“大脑”(LLM)会_阅读_这个描述,来决定是否以及如何调用这个工具。
-
具体的运行流程和返回结果:函数体本身。
举个例子,我们用 LangChain 提供的 @tool 装饰器来快速定义一个“查询天气”的工具:
|
|
Step 2: 创建 Tool_List 列表,注册工具
你已经打造好了工具(calculator)(get_current_weather),现在得把它们放进一个“工具箱”,交给 Agent。
这一步很简单,就是把所有创建好的工具函数放进一个列表(List)里:
|
|
这个 tools 列表会被传递给 Agent。Agent 在思考时,就会“浏览”这个列表里的所有工具描述,智能决策
Step 3: 使用 LCEL 构建 Agent 的核心推理组件
这一步是 Agent 的关键所在。我们要把模型(LLM)、工具(Tools)、**提示词(Prompt)和解析器(Parser)**组装起来,构建一个“推理链”。
在 LangChain 中,我们使用 LCEL (LangChain Expression Language) 这种“管道符 |”风格来组装链。
虽然你可以手动组装(如下面注释掉的 LCEL 结构),但 LangChain 提供了一个非常方便的快捷方式:create_tool_calling_agent。
它封装了以下所有逻辑:
-
prompt: 一个内置的、高质量的提示词模板(当然你也可以自定义),它会告诉 LLM 如何扮演一个 Agent 并如何使用工具。 -
llm.bind_tools(tools): 这是关键一步,它把你的工具列表“绑定”到 LLM 上,让 LLM 知道这些工具的存在,并能在它的输出中生成特定的“工具调用”请求。 -
OutputParser: 一个输出解析器,用于解析 LLM 返回的“思考过程”或“工具调用请求”。
Python
|
|
现在,agent_chain 就成了 Agent 的核心推理组件。你给它 input 和 agent_scratchpad(历史记录),它就会返回下一步的决策(是回答用户,还是调用工具)。
Step 4: 创建 AgentExecutor,管理循环和执行
AgentExecutor 负责管理 ReAct 循环:
-
它把用户的输入(Input)丢给
agent_chain。 -
agent_chain返回一个决策(比如:Action: call get_current_weather(location='北京'))。 -
AgentExecutor捕获这个决策,暂停 LLM,然后真正地去 Python 环境中执行get_current_weather('北京')函数。 -
执行器拿到返回结果(
Observation: "北京今天晴,25摄氏度。")。 -
它把这个结果塞进
agent_scratchpad,再次调用agent_chain。 -
agent_chain看到新的观察结果,再次思考:“OK,拿到天气了,现在我可以回答用户了。” -
agent_chain返回最终答案。 -
AgentExecutor看到是大脑的最终答案(Finish),于是将结果返回给用户。
|
|
当你运行 agent_executor.invoke 时,如果你设置了 verbose=True,你将在控制台看到 Agent 完整的 ReAct 思考过程。
就这样,我们从零到一,使用 LangChain 成功构建并运行了一个具备“思考”和“行动”能力的智能 Agent。
3. Agent 运行的主要流程
在上一节,我们创建并运行了 AgentExecutor。我们只管 invoke,它就自动完成了一系列复杂的交互。这种便捷的背后,是一套被精确定义的、基于“工具调用”(Tool Calling)的循环机制。
AgentExecutor 扮演的,是一个精密的**调度器(Orchestrator)**角色。它负责管理整个工作流,确保 LLM 的决策 Reason 和工具的 Act 能够正确衔接。
我们来拆解一下这个 AgentExecutor 运行时的 ReAct Loop ,看看它在技术上是如何实现的。
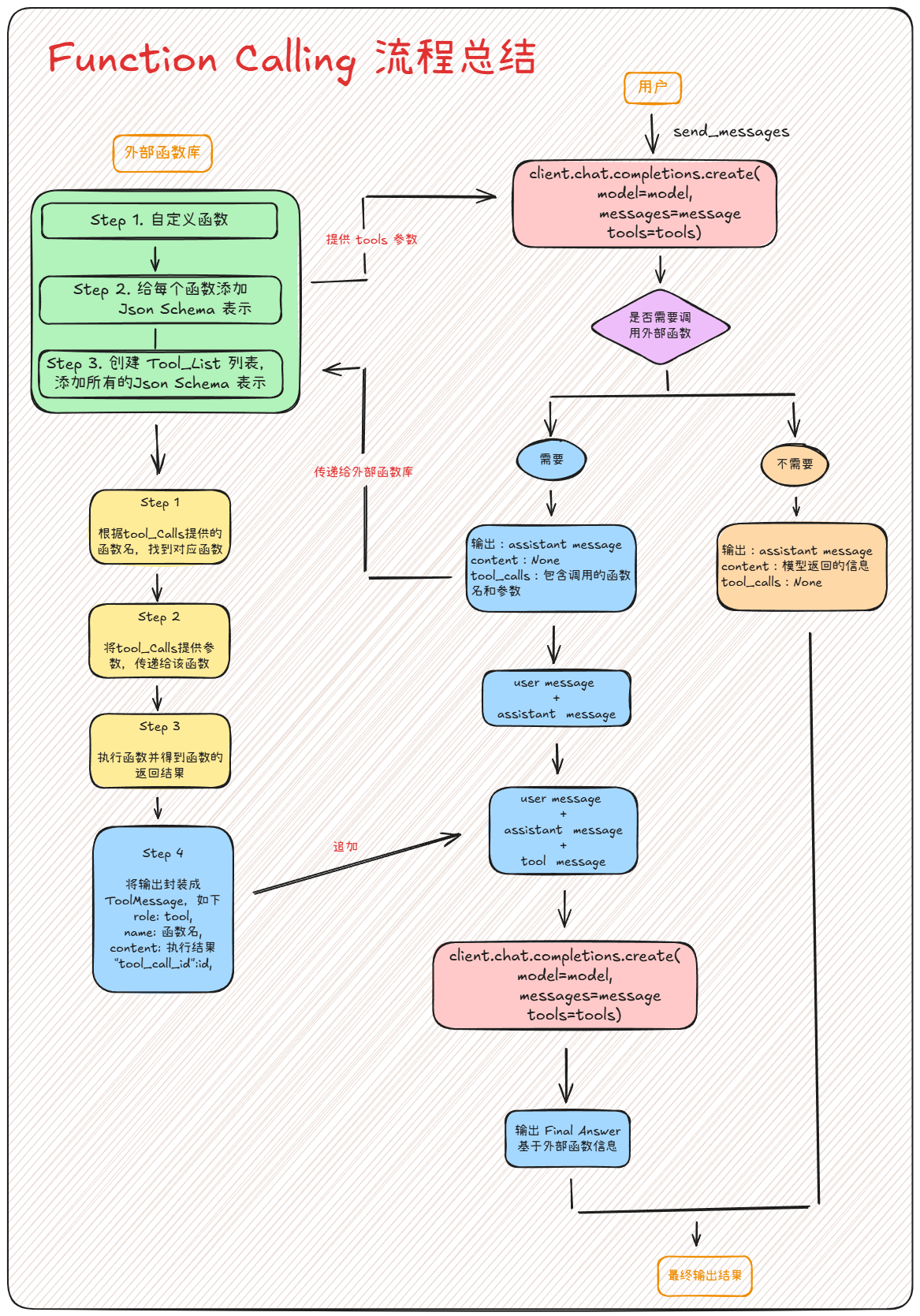
步骤一:用户请求与首次模型调用
-
用户发起请求:用户输入 “北京今天天气怎么样?”
-
AgentExecutor接收任务:它获取这个input。 -
调用核心推理链:
AgentExecutor将用户的输入,连同我们定义的tools列表,一起传递给agent_chain。 -
agent_chain内部:prompt模板被填充,然后 LLM 被调用。最关键的是,在这次 API 调用中(例如调用 OpenAI API),tools参数被传入。这等于告诉 LLM:“你具备了调用这些工具的能力。”
步骤二:模型决策(是否使用工具?)
LLM 在分析了用户的输入和可用的工具描述后,会返回一个决策。这里会产生两个分支:
分支 A:不需要工具(直接回答)
-
场景:例如用户输入“给我讲个笑话”。
-
LLM 决策:LLM 判断仅凭自身知识库即可回答。
-
LLM 输出:模型返回一个标准的
Assistant消息。其content字段包含笑话内容,而tool_calls字段为None。 -
AgentExecutor动作:AgentExecutor检查到这是一个最终答案(Finish状态),于是将content作为output返回给用户。流程结束。
分支 B:需要工具(请求调用)
-
场景:例如用户输入“北京今天天气?”
-
LLM 决策:LLM 识别到这需要外部信息,并匹配到了
get_current_weather工具。 -
LLM 输出:这是关键。模型返回的
Assistant消息中,content字段是None。取而代之的是,tool_calls字段会包含一个(或多个)结构化对象,这本质上是一个函数调用请求。 -
“函数调用请求”的结构:
-
function.name: 要调用的函数名,如get_current_weather。 -
function.arguments: 一个包含参数的 JSON 字符串,如{"location": "北京"}。 -
id: 一个唯一的调用 ID,如tool_call_id_abc123。这个 ID 用于后续追踪。
-
步骤三:工具的本地执行
AgentExecutor 作为调度器,当它收到 LLM 返回的 tool_calls 请求时,它知道现在轮到它在本地执行代码了。
-
解析请求:
AgentExecutor遍历tool_calls列表。 -
匹配与执行:它根据请求中的
function.name(get_current_weather),从我们提供的tools列表中找到对应的 Python 函数。 -
传递参数:它解析
function.arguments({"location": "北京"}),并将这些参数传递给该 Python 函数并执行它。 -
获取结果:函数在本地运行,并返回一个结果,例如:
"北京今天晴,25摄氏度。"
步骤四:结果回传与第二次模型调用
拿到工具的执行结果后,AgentExecutor 并不会直接将其返回给用户。它需要将这个新信息反馈给 LLM,让 LLM 来决定下一步做什么(是继续调用其他工具,还是总结答案)。
-
封装“工具消息” (Tool Message):
AgentExecutor将刚才的函数执行结果,封装成一个符合规范的新消息。这个消息必须包含:-
role:'tool'(表明这是一个工具的返回结果) -
content: 函数的返回值 (e.g.,"北京今天晴,25摄氏度。") -
tool_call_id: 必须是步骤二中 LLM 返回的那个id(tool_call_id_abc123)。这至关重要,它让 LLM 能够将结果与它之前的调用请求对应起来。
-
-
追加历史并再次调用:
AgentExecutor将这个Tool Message添加到“草稿纸”(agent_scratchpad)中,这维护了完整的上下文。 然后,它再次调用agent_chain,将包含原始问题、LLM 首次调用请求、以及Tool Message的全部历史消息再次发送给 LLM。
步骤五:生成最终答案
-
LLM 综合信息: LLM 这一次接收到了所有上下文:用户的原始问题(“北京天气如何?”)和工具的执行结果(“北京…25度”)。
-
生成最终答案: 基于这些完整的信息,LLM 会用自然语言生成一个对用户友好的、综合性的回答。这次它返回的
Assistant消息中,content字段将包含这个最终答案(例如:“北京今天天气晴朗,气温是25摄氏度。”),而tool_calls字段为None。 -
AgentExecutor输出:AgentExecutor收到这个响应,判断这是一个Finish状态,于是将content作为最终output返回给用户。
至此,一次完整的 Tool Calling 循环结束。AgentExecutor 通过这个严谨的“调用-执行-回传-再调用”流程,实现了 LLM 与外部世界的可靠交互。
另一种方法:基于原生工具调用
除了上面介绍的基于 ReAct 的推理过程,其实还有另一种更先进的agent模式,不过本博客中的实战项目并没有使用这种方式,所以先暂时介绍一下:
对于 GPT-4o、Gemini 等支持原生“Tool Calling”功能的先进 LLM,决策更高效:
-
结构化绑定: 工具通过 Python 函数签名或 JSON Schema 的形式,直接“绑定”到 LLM 上。
-
模型原生判断: LLM 利用其内置能力,直接根据用户意图,生成一个结构化的 JSON 对象,清晰指明要调用的工具名称和参数。
-
精确执行: 这消除了文本解析的错误风险,提高了决策的准确性和速度。
五、项目实战:构建一个“网站总结 PDF 报告” Agent
我们现在就把前面学到的知识组合起来,构建一个有实际价值的自动化流程。
1. 项目的意义
这个项目的目标很明确:你给它一个 URL,它自动访问该网站,阅读并总结内容,最后生成一份排版精美的 PDF 总结报告。
这绝对是一个“懒人福音”。想象一下,你需要调研 10 个竞品网站,手动操作就是:打开、阅读、复制、粘贴、排版… 而现在,你只需要一个 URL 列表。
并且这个项目也有很大的 学习价值:这个项目能帮我们完美串联起前面介绍的 Agent 的核心概念。
2. 总体构建思路
我们的策略不是构建一个庞大的“超级 Agent”。我们将遵循“Unix 哲学”:创建小而精的工具,然后用“链”将它们连接起来。
本实战中的工具 (Tools):
-
工具 A (
summarize_website):一个“网站总结工具”。它接收一个url,然后打开一个浏览器(我们使用 Playwright)来访问它(这能访问那些 JS 渲染的“现代”网页),提取文本,并调用 LLM 对文本进行总结。最后,它返回总结好的字符串。 -
工具 B (
generate_pdf):一个“PDF 生成工具”。它接收一段文本内容 (content),使用reportlab库将其排版(包括处理中文字体),并保存为一个带时间戳的 PDF 文件。最后,它返回生成的文件路径字符串。
本项目中构建的Chains:
我们将构建两条Chains来对比效果:
-
简单功能Chains:
summarize_website|generate_pdf-
流程:网站总结工具的输出(总结文本)被直接用作 PDF 生成工具的输入。
-
优点:简单、快速。
-
缺点:总结的原始文本可能格式比较乱,直接塞进 PDF 不够美观。
-
-
优化的Chains:
summarize_website| LLM 优化 |generate_pdf-
流程:在总结和生成 PDF 之间,我们插入一个额外的 LLM 调用。这个 LLM 的任务是把原始总结润色和排版成更适合报告的格式(比如加上标题、要点)。
-
优点:生成的 PDF 报告质量更高,更专业。
-
3. 核心代码解析
(这里仅有代码的关键片段用于介绍,完整代码我后续会放到 文末GitHub 地址中供大家参考。)
第 1 部分:summarize_website
这是我们第一个工具,也是最“秀”的一个。我们用 @tool 装饰器来定义它:
|
|
介绍:我们没有自己去写复杂的 Playwright 爬虫代码。我们利用了 LangChain 提供的 PlayWrightBrowserToolkit,它已经把“访问页面”、“提取文本”等操作封装成了 Agent 可用的 tools。
我们在这个 @tool 函数内部,又创建并运行了一个 Agent。这就是或“Agent-as-a-Tool”模式:从我们主流程的视角看,summarize_website 只是一个工具;但在这个工具内部,其实是一个完整的 Agent 。
第 2 部分:generate_pdf
这个工具相对简单,它就是一个 Python 函数,负责调用 reportlab 库生成 PDF。
|
|
介绍:在 Agent 开发中,经常需要写这类“胶水”工具,把 Python 的生态(如 PDF、Excel、API 调用)封装起来,供 LLM 使用。处理中文字体是这类任务中一个非常经典的“坑”。
第 3 部分:LCEL 组装chains
这是最能体现 LangChain 特点的地方。我们用 | 管道符来连接我们的各个模块。
|
|
4. 运行结果与分析
当我们使用一个 GitHub README 的 URL (https://github.com/fufankeji/MateGen/blob/main/README_zh.md) 来运行这个项目时:
AgentExecutor 开始工作。
如果选择“简单chains”:
-
控制台打印
📝 步骤1: 网站总结... -
summarize_website工具被调用。其内部的“浏览器 Agent”开始访问 URL、提取文本、并调用 DeepSeek 总结。 -
它返回了总结的原始文本。
-
控制台打印
📄 步骤2: 生成PDF... -
generate_pdf工具被调用,它把这段原始文本写进了 PDF。 -
结果:我们得到了一个 普通的总结PDF。
如果选择 “优化chains"
-
控制台打印
📝 步骤1: 网站总结...(同上) -
summarize_website返回原始总结。 -
控制台打印
🎨 步骤2: 内容优化... -
LCEL 链自动将原始总结(通过
lambda和optimization_prompt)发送给 DeepSeek 模型。 -
DeepSeek 扮演“编辑”角色,返回了结构化、排版优美的文本(例如:“\n## 1. 主要功能\n- 功能A…\n- 功能B…\n## 2. 特点\n…”)。
-
控制台打印
📄 步骤3: 生成PDF... -
generate_pdf工具接收到这个优化后的文本,并生成 PDF。 -
结果:我们得到了一个排版清晰、带有标题和分点的专业 PDF 报告。
如下图所示

###项目小结
这次关于LangChain和agent的学习与实战 ,让我彻底搞懂了 Agent 这个是怎么指挥 LLM和 Tools干活的。通过 ReAct 和 Tool Calling 机制,设计出严谨的工作流。从理论到实战,当我们把浏览器 Agent、LLM 润色和 PDF 工具用 LCEL 串联起来,看着 URL 自动变成一份精美的网页 PDF 报告时,非常直观地感受到了agent的巨大潜力。之后也会继续学习agent的相关内容并继续发布博客的。
( ๑╹ ꇴ╹) グッ!
💻项目源码
💻 项目源码可以访问我的Github:Langchain_Agent